PCA application sample for analysis of stock markets using python
PCA is a mathematical method for compressing multidimensional data into a less dimensional version. That data reduction helps to make analysis more simpler. More information about principle component analysis and its math is here. With this project I tried to analyse stock market data with PCA decomposition.
# Data
I used "Borsa Istanbul 100" a.k.a. "Bist100" stock market index symbols. It is an index of Turkey stocks that covers top 100 biggest components. Gathered 5 basic financial ratios for each symbol around internet and here is the raw result (ticks.raw.csv):
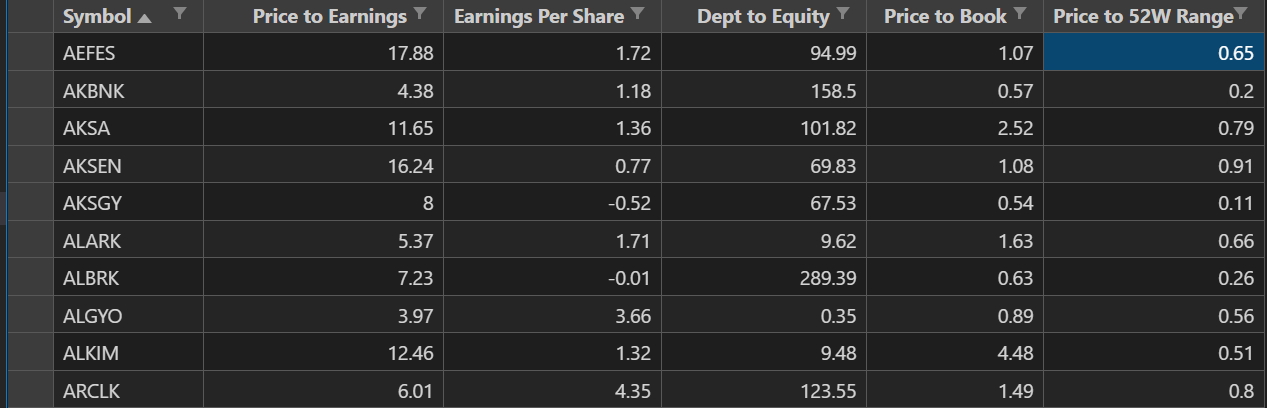
These are some common financial indicators to measure fair price of a company. I picked 5 of many indicators which i wanted in my sample analyse. Different choices made among the indicators will change the whole result.Therefore, it is important to make the right choices. Raw data columns has various ranges. For instance price to earning range is 1.43 to 244.74 and price to book value range is 0.29 to 30.51. Too much numerical difference between columns affects their impact on the result which is not wanted. Thats why applied following steps to balance them:
- Normalize each ratio indicator in its own column to fit 0 to 1
- Crop extreme high/lows fixed limit
- After normaliztion 1 should be the best and 0 should be the worst value for each column but for some ratios lower value is better. For price to book value,dept to equality,price to book, price to 52W range lower is better. Therfore subtracted their normalized value from 1 for these columns
Here is the result (ticks.norm.csv):
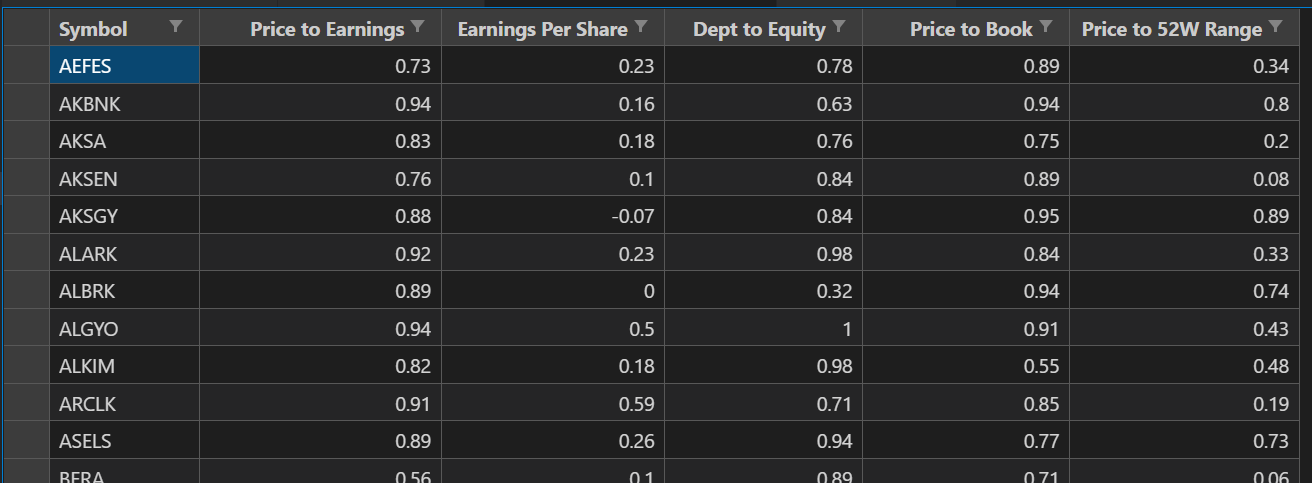
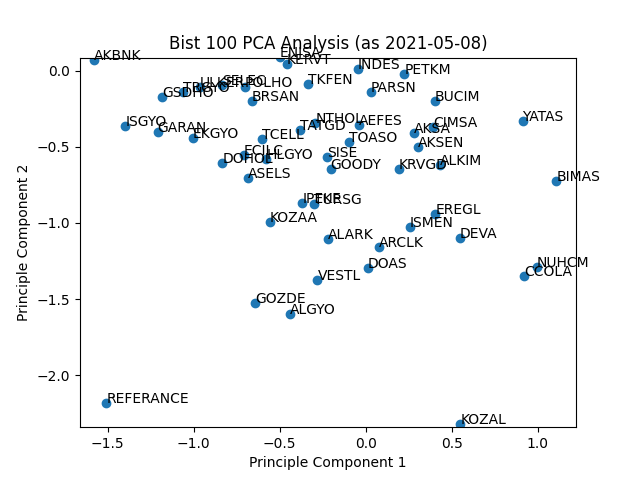
Afer data fetch and normalization I pushed an other single row to final data. It is "Referance" point. An imaginary stock with perfect ratios. All the indicators equals to 1. That point will help me to figure out better stocks after PCA decomposition.

# PCA
Raw data contains one label dimension (symbol column) and 5 feature dimensions. With PCA calculation, reduced that information to 2 component dimentions. These dimentions contains primary characteristic information of whole 6 dimention data. Sklearn liblary has built in PCA tools to make that happened. Pandas and matplotlib will help to visualize reduced data in scatter plot. These steps in pca.py file. Here is the result plot:
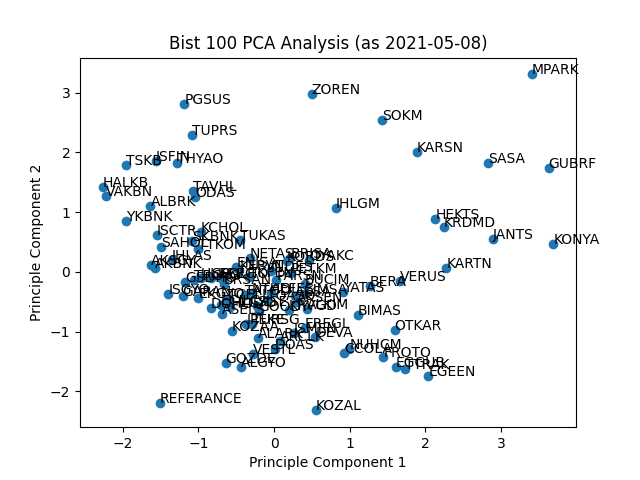
Closer to Referrance point means better results: